ORCID Phase 1 Query API
Authors: Michael Taylor (mi.taylor@elsevier.com), Geoffrey Bilder (gbilder@crossref.org)
V1: 4-JUL-2011
V2: 4-AUG-2011 (corrected mime types)
V3: 11-AUG-2011 (updated following API meeting August 9th)
V4: 26-AUG-2011 (some further updates based on August 9th meeting and emails)
V5: 20-SEP-2011 (correcting curl url strings to remove reference from content in header)
V6: 28-SEP-2011 (made public)
V7: 18-OCT-2011 (changed “Authorization: OAuth” to “Authorization: Bearer” as per spec.
V8: 26-OCT-2011 (added JSON access token details)
V9: 2-NOV-2011 (updated URLs, and changed accept header for search API)
V10: 17-JAN-2012 (Removed option to authenticate using IP and API key)
V11: 15-FEB-2012 (Removed x- from mime-types)
V12: 19-APR-2012 (Added search API details)
v13: 24-APR-2012 (Added email address as search field)
v14: 21-AUG-2012 (Updated to match schema version 1.0.3)
v15: 29-Aug-2012 (Updated to update terminology inconsistencies with other documents)
Introduction
This documents describes the application programmer interface (API) for querying and searching the ORCID system. This API will allow third parties to integrate ORCID profiles into their submission and evaluation systems.
Separate documents will describe ORCID APIs for enabling third parties to batch deposit records into the system as well as the API which third parties will need to support in order to allow ORCID users to import profile data from their systems.
Note: where this document refers to researchers, paper authors or contributors, it does so interchangeably. Our intention is to refer to those individuals who have made a scholarly contribution.
Warnings, Caveats and Weasel Words
This is preliminary documentation and has been produced as the first draft of a specification for a system that does not yet exist. In short, there is no ORCID API yet, so please don’t attempt to experiment with the system using this documentation, you will just be disappointed.
Having said that, our goal is to get this specification robust enough so that we can get a development team to create a working sandbox version of the API (aka “Mock API”) as soon as possible. This will allow third parties to start their integration efforts in parallel with the rest of ORCID’s phase 1 development. The proposed sandbox functionality is explained in appendix A.
Terminology
Private data
Profile data that the user has chosen to restrict access to. This data may be used in hashed, anonymized form for internal disambiguation purposes by the ORCID system, but it will not be made available to third parties or the public.
Protected data
Profile data that the user chooses to share with selected third parties (e.g. specific funding agencies, publishers, etc.) but which is not made available publicly.
Public data
Profile data that the user chooses to make available to the public. This data will be made available under a CC-zero waiver via APIs and via periodic data dumps.
Public API
The API made available to the general public and which can be used without any sort of authentication. This API will only return data marked by users as “public” and will come with no service level agreement (SLA). The API may be throttled at the IP / transaction level in order to discourage inadvertent overloading and/or deliberate abuse of the system.
Member API
The API made available to third parties requiring production-level integration of the ORCID service. The API will come with defined service level agreements and will allow authenticated third parties to retrieve “protected” profile data from those users who have authorized them to do so.
The Member API will be architecturally isolated from the Public API in order to allow separate scaling to meet SLA requirements.
Bio Record
The default result when querying the ORCID APIs will be to return “bio records”. Bio records only include biographical information relating to the ORCIDs (subject to the user’s privacy settings) and do not include activities (publications, patents, grants). This default behavior is designed to minimize the size of returned records for default queries and will work the same in both the Public and Member APIs.
Works
The list of “works” for this ORCID: published articles, books or other documents for which this person was recognized as a contributor. Privacy settings can apply to these relationships as well, so the response list can depend on the entity making the query.
Full Record
This is provided for convenience so that a single request includes *both* the biographical information and activities information (subject to the user’s privacy settings) related to the ORCIDs queried.
HTML
- Web pages will be semantically marked-up using schema.org microdata.
- They will be freely accessible webpages.
Overview
The ORCID query APIs will enable third parties to search the system and obtain data through a simple RESTFUL[1] interface. The interface will support the following query types:
Name | Key | Returned | Description |
Bio | ORCID | Profile metadata | Given a contributor, give me name and affiliation data. |
Works | ORCID | List of work metadata | Given a contributor, tell me what works they have contributed to. |
Full | ORCID | Profile metadata, activities metadata and ORCIDs | Given an contributor, tell me what activities they have contributed to, name and affiliation data. |
Work | Work identifiers (e.g. DOIs) | ORCIDs & associated metadata | Given a work, tell me what contributors are responsible for it. |
Search | ORCID, Work identifiers, or profile metadata | ORCIDs & associated metadata | Given whatever metadata I have, give me a ranked list of potential contributors identified by that metadata. |
The Public API will require no authentication on the part of those querying it, while the Member API will require third parties to authenticate using the OAuth2 open standard for authentication between computer systems.
Using the Public ORCID Query API
The ORCID APIs will support returning ORCID records in various representations, including, to start with, HTML, XML and JSON. The preferred representation of the record can be specified using content negotiation. Examples of the XML representation of both bio and full responses can be found at:
http://orcid.github.com/ORCID-Parent/schemas/orcid-message/1.0.3/
Users of the API will be able to specify the particular version of a representation that they are expecting. This will enable ORCID to change the representations (e.g. by adding, moving or removing elements, etc.) without breaking third party applications which are expecting particular representations. Note carefully that the “version” refers to the version of the representation of the record returned - not the version of the record itself.
The following examples illustrate querying the Public ORCID Query APIs using the command line tool, curl[2]. Note that all of the queries below will only return data that users have marked as being “public.”
Note inclusion of examples that specify type request in URL alone.
Example 0: Request the HTML representation of an ORCID profile
curl -H "Accept: text/html" "http://api.orcid.org/{orcid}/orcid-bio" -D - -L
Example 1: Request an XML representation of the “bio record” for an ORCID
curl -H "Accept: application/orcid+xml" "http://api.orcid.org/{orcid}/orcid-bio" -D - -L
Example 2: Request the JSON representation of the “bio record” for an ORCID
curl -H "Accept: application/orcid+json" "http://api.orcid.org/{orcid}/orcid-bio" -D - -L
Example 3: Request XML representation version 1.1 of the “bio record” for an ORCID
curl -H "Accept: application/orcid+xml ; version=1.1" "http://api.orcid.org/{orcid}/orcid-bio" -D - -L
Example 4: Asking XML representation 1.1 of the “full record” for an ORCID
curl -H "Accept: application/orcid+xml ; version 1.1" "http://api.orcid.org/{orcid}/orcid-profile" -D - -L
Example 5: Request an XML representation of the “works” for an ORCID
curl -H "Accept: application/orcid+xml" "http://api.orcid.org/{orcid}/orcid-works" -D - -L
Searching using the ORCID Public API.
The ORCID API will support searching a subset of ORCID metadata using the popular SOLR query syntax.
Query syntax
The ORCID search API will be based on SOLR, and will support all query syntaxes available in SOLR 3.6, including the following.
- Lucene with SOLR extensions
- DisMax
- Extended DisMax
The default syntax will be Lucene with SOLR extensions.
Search URL
The base URL for searching will be as follows. SOLR query parameters will be appended to this URL.
http://api.orcid.org/search/orcid-bio/
Search results format
The results of the search will be a list of “bio records” in the same format returned by the REST API call for a single record, described above. Each bio in the list will have a relevancy score, as determined by SOLR.
The search API will use content negotiation to determine whether to return XML or JSON, in the same way as the REST API calls for a single record.
Search fields
SOLR field name | XPath for corresponding profile data | Description |
orcid | //orcid-profile/orcid | The ORCID identifier for the researcher or contributor. |
given-names | //orcid-profile/orcid-bio/personal-details/given-names | The given names of the researcher of contributor |
family-name | //orcid-profile/orcid-bio/personal-details/family-name | The family name of the researcher of contributor |
past-institution-affiliation-name | //orcid-profile/orcid-bio/affiliations/affiliation[affiliation-type="past-institution"]/affiliation-name | The name of any past institution in the researcher or contributor’s profile |
current-primary-institution-affiliation-name | //orcid-profile/orcid-bio/affiliations/affiliation[affiliation-type="current-primary-institution"]/affiliation-name | The name of the primary institution of the researcher or contributor |
current-institution-affiliation-name | //orcid-profile/orcid-bio/affiliations/affiliation[affiliation-type="current-institution"]/affiliation-name | The name of non-primary institutions of the researcher or contributor |
credit-name | //orcid-profile/orcid-bio/personal-details/credit-name | The name that normally appears on publications by the researcher or contributor |
other-names | //orcid-profile/orcid-bio/personal-details/other-names | Alternative names that may have appeared on publications by the researcher or contributor |
//orcid-profile/orcid-bio/contact-details/email | The email address of the researcher or contributor | |
digital-object-ids | //orcid-profile/orcid-activities/orcid-works/orcid-work/work-external-identifiers/work-external-identifier[work-external-identifier-type="doi"]/work-external-identifier-id | The DOI of any work in the researcher or contributor’s profile |
work-titles | //orcid-profile/orcid-activities/orcid-works/orcid-work/work-title/(title|subtitle) | The titles of any work in the researcher or contributor’s profile |
grant-numbers | //orcid-profile/orcid-activities/orcid-grants/orcid-grant/grant-number | The grant number of any grant associated with the researcher or contributor |
patent-numbers | //orcid-profile/orcid-activities/orcid-patents/orcid-patent/patent-number | The patent numbers of any patent associated with the researcher or contributor |
keywords | //orcid-profile/orcid-bio/keywords/keyword | Any keywords associated with the researcher or contributor |
text | All the above data are combined into this field | All the above fields. This is also the default field for Lucene syntax queries. |
Example queries
Name | Example 1 |
Description | Search family names of all ORCID records for the name ‘Carberry’ |
Syntax | Lucene |
Paging | First 10 rows only |
URL | http://api.orcid.org/search/orcid-bio/?q=family-name:Carberry&start=0&rows=10 |
Name | Example 2 |
Description | Search all searchable fields of all ORCID records for the word ‘Carberry’ |
Syntax | Lucene |
Paging | First 10 rows only |
URL | http://api.orcid.org/search/orcid-bio/?q=text:Carberry&start=0&rows=10 |
Name | Example 3 |
Description | Search family names of all ORCID records for the name ‘Carberry’ and the keyword ‘Physics’. Only records containing both the family name and the keyword will be returned. |
Syntax | Lucene |
Paging | First 10 rows only |
URL | http://api.orcid.org/search/orcid-bio/?q=family-name:Carberry%20AND%20keyword:Physics&start=0&rows=10 |
Name | Example 4 |
Description | Search given names and family names of all ORCID records for ‘Raymond’ but boost the family name. Records with given names containing ‘Raymond’ and family name containing ‘Raymond’ will be returned, but those with family name will appear at the top of the list and will have a higher relevancy score. |
Syntax | Extended DisMax |
Paging | First 10 rows only |
URL | http://api.orcid.org/search/orcid-bio/?defType=edismax&q=Raymond&qf=given-names^1.0%20family-name^2.0&start=0&rows=10 |
Name | Example 5 |
Description | Search given names and family names of all ORCID records for ‘Raymond’ but boost the family name. Records with given names containing ‘Raymond’ and family name containing ‘Raymond’ will be returned, but those with family name will appear at the top of the list and will have a higher relevancy score. The two records with ORCID ID 281877-5816-0747-5659 and 6181-9093-3346-6284 will be excluded from the results. |
Syntax | Extended DisMax |
Paging | First 10 rows only |
URL | http://api.orcid.org/search/orcid-bio/?defType=edismax&q=Raymond%20-orcid:%281877-5816-0747-5659%206181-9093-3346-6284%29&qf=given-names^1.0%20family-name^2.0&start=0&rows=10 |
The search API will support opensearch in version 1.1 of the API release.
Using the Member ORCID Query API
The Member ORCID Query API will allow authenticated third parties to retrieve “protected” data from the profiles of researchers who have explicitly agreed to share their data. In order to use the API to query for protected data, the third party will first have authenticate using the OAuth protocol.
OAuth
OAuth is an open standard for authorization between computer systems. Technology built using OAuth allows users to share their private resources stored on one system with another one without having to use credentials, (username, password, etc). Once a relationship between two systems has been approved, that relationship is remembered via a process of retaining exchanged secure tokens. Either side may revoke the relationship in the future.
For example, when installing a Facebook or Twitter application on a smartphone, you’ll often go through a simple mechanism of using your username and password to establish that relationship - and after this, in your Facebook or Twitter application pages, you’ll see that relationship between phone and web service listed, detailed and revokable. The process feels just like a simple username / password login to the user, but the underlying technology protocol is far more complex and secure.
ORCID will utilize OAuth 2. At the time of writing the current specification version is v2-22, and can be found at: http://tools.ietf.org/html/draft-ietf-oauth-v2-22
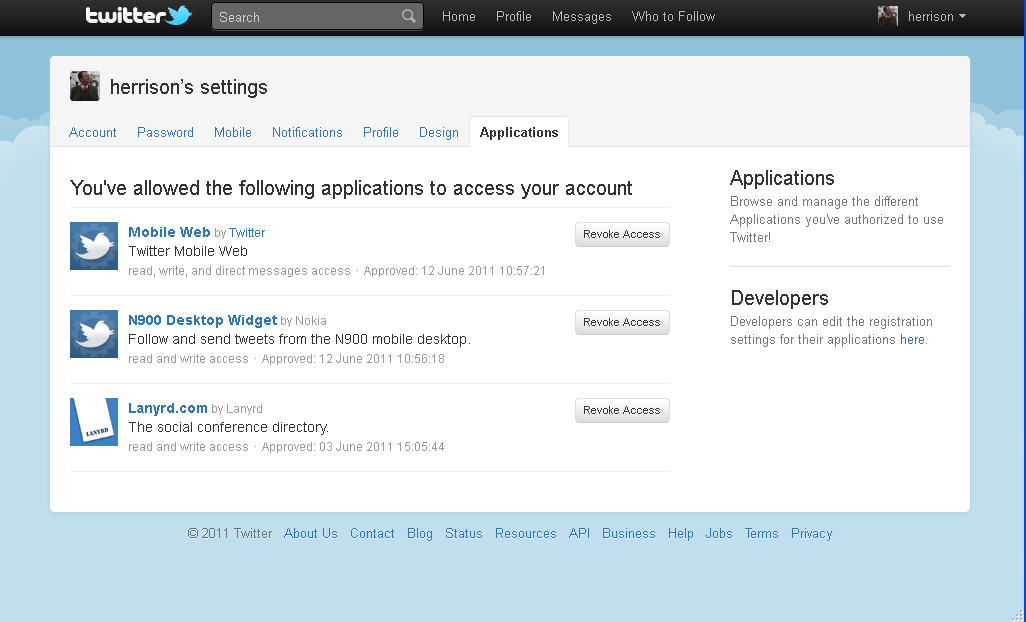
Twitter settings page. The user has granted access to three applications to share data with Twitter via OAuth. Permission may be revoked either at Twitter or on the applications.
It is proposed that Orcid uses Oauth to establish relationships between itself and partners who have the authority to access and use the Member API data interface. Once the relationship is made, it is permanent until such time it is revoked (for example at the end of a subscription period, contract, terms and conditions infringements, etc).
OAuth is used by Google, Microsoft, Facebook, Yahoo and Twitter to control to their APIs.
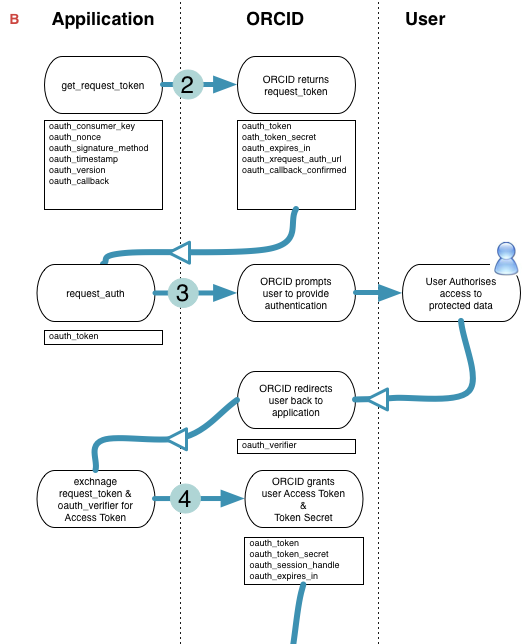
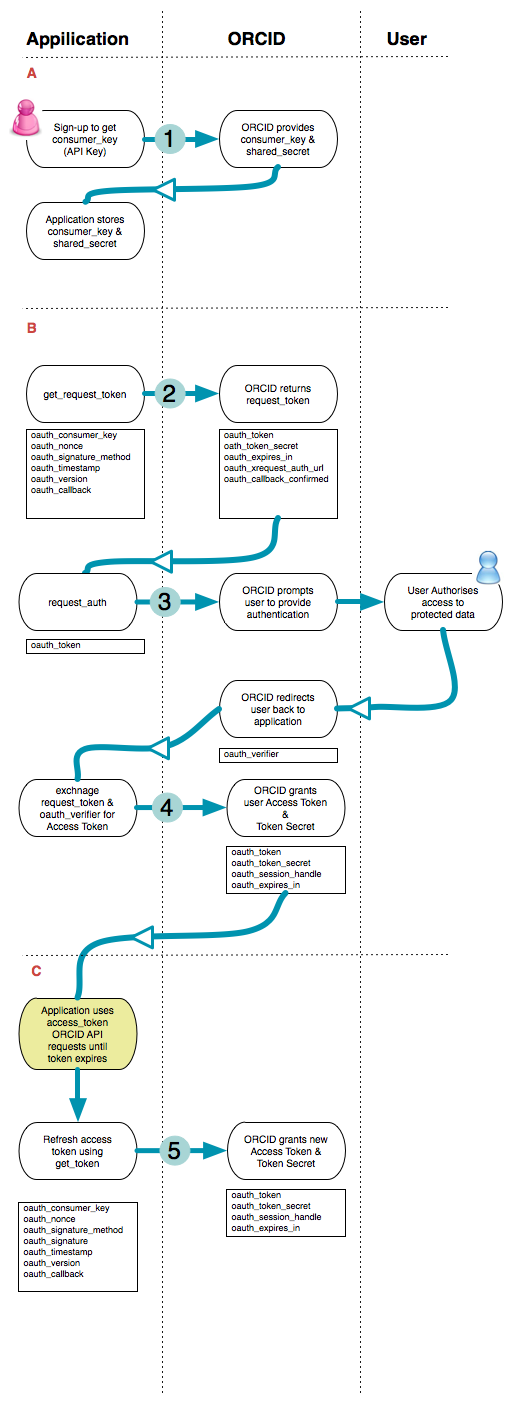
An overview of the entire Oauth work flow can be seen in appendix B.
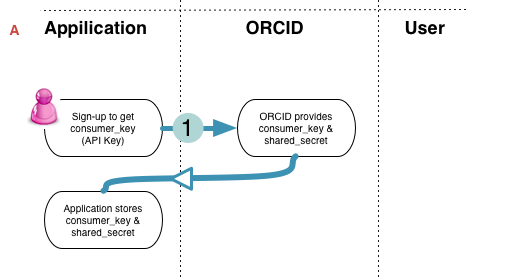
Obtaining An Oauth Consumer (API) Key
In order for a third party to query the Member API ORCID Query API, they will first need to obtain a Consumer Key from the ORCID service. The ORCID system will provide a web interface which will allow authorized third parties to generate Consumer Keys for their applications.
For Example, the Society of Psychoceramics, who wants to to be able to integrate ORCID into their manuscript submission process, would go to a form on the ORCID site and fill in relevant information.
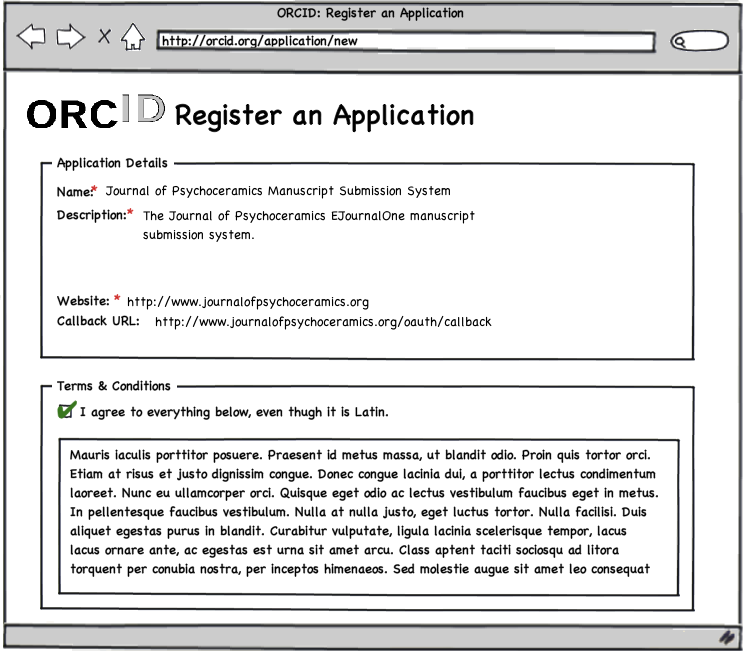
Upon submitting this information, the developers at the Society for Psychoceramics would be returned to a page listing all the relevant keys and API end-points needed in order to authenticate their users against the ORCID system.
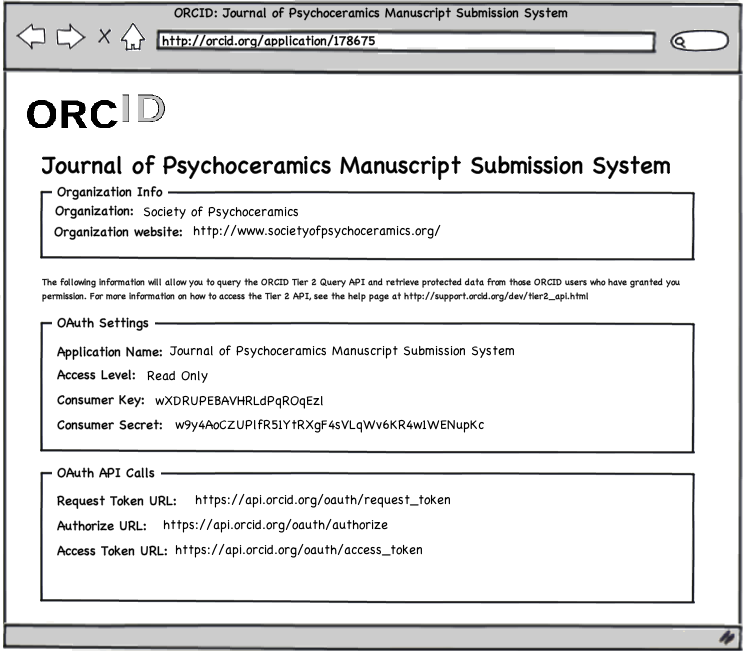
Once the developer has generated the needed application Consumer Keys, they can start to integrate ORCID into their own systems.
In summary, the flow for obtaining a Consumer Key looks like this:
Retrieving Protected Data
The Member API allows third parties to query the ORCID API and retrieve protected data from the profiles of those ORCID users that have authorized them to do so. This means that third parties will need to support a process that allows ORCID users to explicitly authorize them to access protected profile data. Once an ORCID user has authorized a particular third party to have access to their protected data, then the third party can query said data without having to go through the authorization process again. That is- unless the ORCID user (or ORCID itself) revokes the third parties authorization.
The process of authorizing a third party to access protected data involves a simple workflow.
For example. Josiah Carberry submits his first manuscript to the Journal of Psychoceramics. The manuscript submission system can offer to expedite the submission process by importing his ORCID profile information.
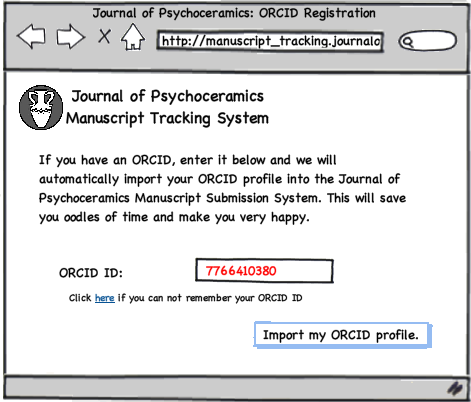
The manuscript tracking system will then redirect Josiah Carberry to the ORCID site where, if he hasn’t already, he is prompted to authenticate and log-in.
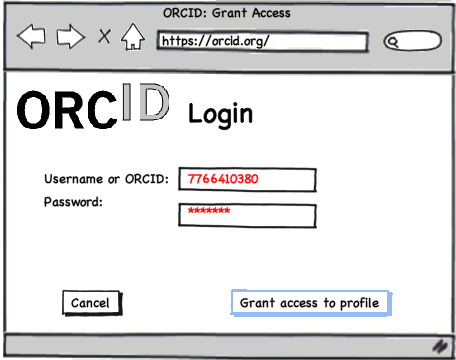
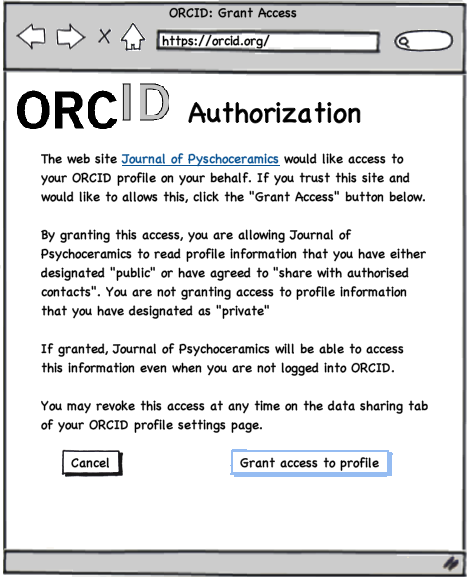
Once Josiah has authenticated with ORCID, the ORCID system will ask him if he wants to share his protected profile information with the Journal of Psychoceramics Manuscript Tracking system. At this point, the Journal of Psychoceramics Manuscript Tracking System will be authorized to generate an “access token”. When requesting this, it will also return the user’s ORCID, thus allowing the system to verify and, or omit the necessity for the user to supply their ORCID.
The JSON response for the access token request will be similar to:
{
"access_token": "5a7a4062-3d26-4b10-aa6d-3d48458535c5",
"expires_in": 43199,
"orcid": "4444-4444-4444-4",
"refresh_token": "007e7701-769b-461d-bac4-ed8133003e49",
"scope": "read",
"token_type": "bearer"
}
The access token will allow access to the protected data within the user’s ORCID profile.
A summary of the above workflow is:
Once Josiah grants permission for the Journal of Psychoceramics manuscript tracking system to query his protected profile, then the manuscipt tracking system will be able to query Josiah’s profile as often as it likes, without re-authenticating, until either Josiah or ORCID revokes the Journal’s permissions. So, once Josiah has authorized the Journal- then the work-flow simplifies to this:
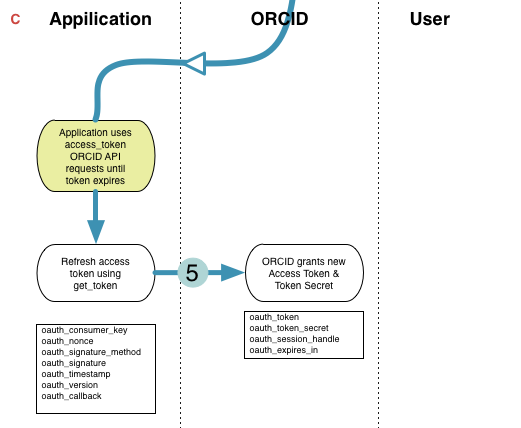
This latter transaction would be accomplished using curl as follows:
curl curl -H "Accept: application/orcid+xml" -H "Authorization: Bearer {YOUR_ACCESS_TOKEN}" “https://api.orcid.org/{orcid}" -D - -L
All such queries will honor the researcher’s privacy settings. That is, profile data that the researcher marks as “private” will not be shared with anybody. Profile data marked as “protected” will only be shared with third parties to whom which the researcher has explicitly granted access. Profile data marked as “public” will be shared with everybody.
Error codes
The following error codes will be implemented in the ORCID API and in the sandbox.
- 400 - Bad request (invalid search syntax)
- 401 - Unauthorized (the application is not authorized to access the resource)
- 406 - Not acceptable (bad accept header, version, etc)
- 413 Request Entity Too Large (search was overly broad and needs to be restricted, partial results may be returned)
- 416 Requested Range Not Satisfiable (bad pagination parameters for search results, other large result list)
- 426 Upgrade required (version the client is requesting is too old)
Appendix A: Sandbox
NB- the “Sandbox API” is now know as the “Mock API” and is available on Github.
A query sandbox will be built at the earliest opportunity to allow partners to develop applications that interface with the Orcid system. The sandbox will:
- Parse query strings, as specified above and respond with appropriate error messages
- Decipher the content preference (web, XML, JSON) and display appropriately.
- Having parsed the query, the sandbox will reply with a static payload.
- Will dummy an OAuth transaction, success or fail.
The sandbox will be maintained and versioned to always support the full set of query strings and response formats.
Sandbox: Response formats
- Web pages will be semantically marked-up using schema.org microdata.
- XML and JSON format detail to be discussed.
- Consideration will be given to inclusion of human-readable messages in response payload files, possibly of url to full message. This would be to enable alerting API clients (particularly public API clients for whom we don’t necessarily have any contact details) to changes in format, functionality, throttling alerts, etc.
- Search responses will be in the form of Orcid IDs plus a match score in the first version. Additional fields will be added in subsequent versions of the API.
Appendix B: Overview of ORCID/OAuth Flow
[1] http://en.wikipedia.org/wiki/Representational_State_Transfer
[2] http://curl.haxx.se/