Now that we’ve highlighted some basic variables in our
Creating Variables series, I think we’re ready to move on to a variable that is
a little trickier to create: retention. The retention variable we’ll create
will represent whether or not a freshman is retained from one fall semester to
the next. Because of the number of different factors you can choose to include
or exclude, I hope that you’ll use these instructions as a general guide rather
than a hard-and-fast manual on how to create a retention variable.
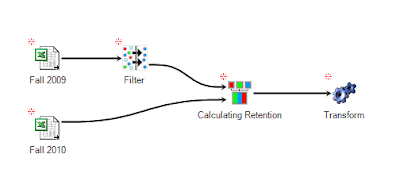
In order to create a fall-to-fall retention variable, we
need to be looking at enrollment data from several consecutive fall semesters.
In order to focus just on freshmen, we’ll start by placing a filter on our
first semester:
Within the filter, you’ll want to focus on the field in your
dataset that represents student year and filter down to just those students who
are freshmen. If you’d like to include other filters here, such as making sure
you’re focusing on first-time freshmen rather than transfer students, or
undergraduate rather than graduate students, this is the time to do so.
The next step is to merge this dataset and filter with the
next consecutive fall semester:
Inside the merge, you’ll want to connect the datasets on an
identifying field, such as student ID. In doing so, you’ll want to take all of
the information about each student from only the first column, so your merge
should look something like this:
Here’s where the magic
happens. After you’ve set up the merge, you need to do one more step before
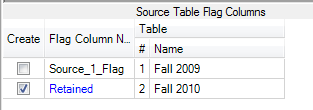
exiting the merge node. See the section titled “Source Table Flag Columns” in
the bottom right corner? That’s where we’re headed. This section allows you to
create a flag variable that tells you which dataset your information came from.
In this case, we’ll create a flag to let us know whenever a student shows up in
both datasets and we’ll call this variable “Retained” (double click on the existing
name to rename it). It should look something like this:
Now we’re getting close, but
we’re not done yet: those of you who have done some predictive modeling
probably know that usually when we talk about retention, we’re actually
planning to model attrition. (So, instead of modeling each student’s likelihood
of leaving, we’d model each student’s likelihood of staying.)Modeling attrition
rather than retention is helpful because we’re focusing on a smaller population
of students and honing in on the characteristics of students who are likely to
leave more directly. To accomplish this, we’ll need to add a transform in order
to create a new attrition variable.
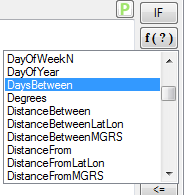
In the transform, we’re going
to set up the attrition variable to be the opposite of the “retained” variable.
To do this, we’ll want to select the “retained” variable to work with and type
the following into the Enter a Formula window: IF (A=1, 0, 1). This basically
turns zeros to ones and ones to zeros. Set the result type to binary and be
sure to name the variable something like “attrition” before creating and
exiting… And there you have it, a state-of-the-art attrition variable to add to
your collection!
-Caitlin Garrett, Statistical Analyst at Rapid Insight















{kind=link}